Webmaster level: All
Starting today, we’re updating our Top Search Queries feature to make it
better match expectations about search engine rankings. Previously we
reported the average position of all URLs from your site for a given
query. As of today, we’ll instead average only the top position that a
URL from your site appeared in.
An example
Let’s say Nick searched for [bacon] and URLs from your site appeared in
positions 3, 6, and 12. Jane also searched for [bacon] and URLs from
your site appeared in positions 5 and 9. Previously, we would have
averaged all these positions together and shown an Average Position of
7. Going forward, we’ll only average the highest position your site
appeared in for each search (3 for Nick’s search and 5 for Jane’s
search), for an Average Position of 4.
We anticipate that this new method of calculation will more accurately
match your expectations about how a link's position in Google Search
results should be reported.
How will this affect my Top Search Queries data?
This change will affect your Top Search Queries data going forward. Historical data will not change.
Note that the change in calculation means that the Average Position
metric will usually stay the same or decrease, as we will no longer be
averaging in lower-ranking URLs.
Check out the updated Top Search Queries data in the Your site on the web section of Webmaster Tools. And remember, you can also download Top Search Queries data programmatically!
We look forward to providing you a more representative picture of your Google Search data. Let us know what you think in our Webmaster Forum.
Monday, February 4, 2013
Update to Top Search Queries data
What’s new with Sitemaps
Webmaster level: All
Sitemaps are a way to tell Google about
pages on your site. Webmaster Tools’ Sitemaps feature gives you
feedback on your submitted Sitemaps, such as how many Sitemap URLs have
been indexed, or whether your Sitemaps have any errors. Recently, we’ve
added even more information! Let’s check it out:
The
Sitemaps page displays details based on content-type. Now statistics
from Web, Videos, Images and News are featured prominently. This lets
you see how many items of each type were submitted (if any), and for
some content types, we also show how many items have been indexed. With
these enhancements, the new Sitemaps page replaces the Video Sitemaps
Labs feature, which will be retired.
Another improvement is the
ability to test a Sitemap. Unlike an actual submission, testing does not
submit your Sitemap to Google as it only checks it for errors. Testing
requires a live fetch by Googlebot and usually takes a few seconds to
complete. Note that the initial testing is not exhaustive and may not
detect all issues; for example, errors that can only be identified once
the URLs are downloaded are not be caught by the test.
In
addition to on-the-spot testing, we’ve got a new way of displaying
errors which better exposes what types of issues a Sitemap contains.
Instead of repeating the same kind of error many times for one Sitemap,
errors and warnings are now grouped, and a few examples are given.
Likewise, for Sitemap index files, we’ve aggregated errors and warnings
from the child Sitemaps that the Sitemap index encloses. No longer will
you need to click through each child Sitemap one by one.
Finally,
we’ve changed the way the “Delete” button works. Now, it removes the
Sitemap from Webmaster Tools, both from your account and the accounts of
the other owners of the site. Be aware that a Sitemap may still be read
or processed by Google even if you delete it from Webmaster Tools. For
example if you reference a Sitemap in your robots.txt file search
engines may still attempt to process the Sitemap. To truly prevent a
Sitemap from being processed, remove the file from your server or block
it via robots.txt.
For more information on Sitemaps in Webmaster Tools and how Sitemaps work, visit our Help Center. If you have any questions, go to Webmaster Help Forum.
Preparing your site for a traffic spike
It’s a moment any site owner both looks forward to, and dreads: a huge surge in traffic to your site (yay!) can often cause your site to crash (boo!). Maybe you’ll create a piece of viral content, or get Slashdotted, or maybe Larry Page will get a tattoo and your site on tech tattoos will be suddenly in vogue.
Many people go online immediately after a noteworthy event—a political debate, the death of a celebrity, or a natural disaster—to get news and information about that event. This can cause a rapid increase in traffic to websites that provide relevant information, and may even cause sites to crash at the moment they’re becoming most popular. While it’s not always possible to anticipate such events, you can prepare your site in a variety of ways so that you’ll be ready to handle a sudden surge in traffic if one should occur:
- Prepare a lightweight version of your site.
Consider maintaining a lightweight version of your website; you can then switch all of your traffic over to this lightweight version if you start to experience a spike in traffic. One good way to do this is to have a mobile version of your site, and to make the mobile site available to desktop/PC users during periods of high traffic. Another low-effort option is to just maintain a lightweight version of your homepage, since the homepage is often the most-requested page of a site as visitors start there and then navigate out to the specific area of the site that they’re interested in. If a particular article or picture on your site has gone viral, you could similarly create a lightweight version of just that page.
A couple tips for creating lightweight pages: - Exclude decorative elements like images or Flash wherever possible; use text instead of images in the site navigation and chrome, and put most of the content in HTML.
- Use static HTML pages rather than dynamic ones; the latter place more load on your servers. You can also cache the static output of dynamic pages to reduce server load.
- Take advantage of stable third-party services.
Another alternative is to host a copy of your site on a third-party service that you know will be able to withstand a heavy stream of traffic. For example, you could create a copy of your site—or a pared-down version with a focus on information relevant to the spike—on a platform like Google Sites or Blogger; use services like Google Docs to host documents or forms; or use a content delivery network (CDN). - Use lightweight file formats.
If you offer downloadable information, try to make the downloaded files as small as possible by using lightweight file formats. For example, offering the same data as a plain text file rather than a PDF can allow users to download the exact same content at a fraction of the filesize (thereby lightening the load on your servers). Also keep in mind that, if it’s not possible to use plain text files, PDFs generated from textual content are more lightweight than PDFs with images in them. Text-based PDFs are also easier for Google to understand and index fully. - Make tabular data available in CSV and XML formats.
If you offer numerical or tabular data (data displayed in tables), we recommend also providing it in CSV and/or XML format. These filetypes are relatively lightweight and make it easy for external developers to use your data in external applications or services in cases where you want the data to reach as many people as possible, such as in the wake of a natural disaster.
Using schema.org markup for videos
Webmaster level: All
Videos are one of the most common types of results on Google and we want
to make sure that your videos get indexed. Today, we're also launching
video support for schema.org. Schema.org
is a joint effort between Google, Microsoft, Yahoo! and Yandex and is
now the recommended way to describe videos on the web. The markup is
very simple and can be easily added to most websites.
Adding schema.org video markup
is just like adding any other schema.org data. Simply define an
itemscope, an itemtype=”http://schema.org/VideoObject”, and make sure to
set the name, description, and thumbnailUrl properties. You’ll also
need either the embedURL — the location of the video player — or the
contentURL — the location of the video file. A typical video player with
markup might look like this:
Video: Title
content="http://www.example.com/videoplayer.swf?video=123" />
Video description
Using schema.org markup will not affect any Video Sitemaps or mRSS feeds
you're already using. In fact, we still recommend that you also use a
Video Sitemap because it alerts us of any new or updated videos faster
and provides advanced functionality such as country and platform
restrictions.
Since this means that there are now a number of ways to tell Google
about your videos, choosing the right format can seem difficult. In
order to make the video indexing process as easy as possible, we’ve put
together a series of videos and articles about video indexing in our new
Webmasters EDU microsite.
For more information, you can go through the Webmasters EDU video articles, read the full schema.org VideoObject specification, or ask questions in the Webmaster Help Forum. We look forward to seeing more of your video content in Google Search.
Safely share access to your site in Webmaster Tools
We just launched a new feature that allows you as a verified site owner to grant limited access to your site's data and settings in Webmaster Tools. You've had the ability to grant full verified access to others for a couple of years. Since then we've heard lots of requests from site owners for the ability to grant limited permission for others to view a site's data in Webmaster Tools without being able to modify all the settings. Now you can do exactly that with our new User administration feature.
On the Home page when you click the "Manage site" drop-down menu you'll see the menu option that was previously titled "Add or remove owners" is now "Add or remove users."

Selecting the "Add or remove users" menu item will take you to the new User administration page where you can add or delete up to 100 users and specify each user's access as "Full" or "Restricted." Users added via the User administration page are tied to a specific site. If you become unverified for that site any users that you've added will lose their access to that site in Webmaster Tools. Adding or removing verified site owners is still done on the owner verification page which is linked from the User administration page.

Granting a user "Full" permission means that they will be able to view all data and take most actions, such as changing site settings or demoting sitelinks. When a user’s permission is set to "Restricted" they will only have access to view most data, and can take some actions such as using Fetch as Googlebot and configuring message forwarding for their account. Restricted users will see a “Restricted Access” indicator at various locations within Webmaster Tools.


To see which features and actions are accessible for Restricted users, Full users and site owners, visit our Permissions Help Center article.
We hope the addition of Full and Restricted users makes management of your site in Webmaster Tools easier since you can now grant access within a more limited scope to help prevent undesirable or unauthorized changes. If you have questions or feedback about the new User administration feature please let us know in our Help Forum.
Keeping your free hosting service valuable for searchers
Webmaster level: Advanced
Free web hosting
services can be great! Many of these services have helped to lower
costs and technical barriers for webmasters and they continue to enable
beginner webmasters to start their adventure on the web. Unfortunately,
sometimes these lower barriers (meant to encourage less techy audiences)
can attract some dodgy characters like spammers who look for cheap and
easy ways to set up dozens or hundreds of sites that add little or no value
to the web. When it comes to automatically generated sites, our stance
remains the same: if the sites do not add sufficient value, we generally
consider them as spam and take appropriate steps to protect our users
from exposure to such sites in our natural search results.

If a free hosting service begins to show patterns of spam, we make a strong effort to be granular and tackle only spammy pages or sites. However, in some cases, when the spammers have pretty much taken over the free web hosting service or a large fraction of the service, we may be forced to take more decisive steps to protect our users and remove the entire free web hosting service from our search results. To prevent this from happening, we would like to help owners of free web hosting services by sharing what we think may help you save valuable resources like bandwidth and processing power, and also protect your hosting service from these spammers:
- Publish a clear abuse policy and communicate it to your users, for example during the sign-up process. This step will contribute to transparency on what you consider to be spammy activity.
- In your sign-up form, consider using CAPTCHAs or similar verification tools to only allow human submissions and prevent automated scripts from generating a bunch of sites on your hosting service. While these methods may not be 100% foolproof, they can help to keep a lot of the bad actors out.
- Try to monitor your free hosting service for other spam signals like redirections, large numbers of ad blocks, certain spammy keywords, large sections of escaped JavaScript code, etc. Using the site: operator query or Google Alerts may come in handy if you’re looking for a simple, cost efficient solution.
- Keep a record of signups and try to identify typical spam patterns like form completion time, number of requests sent from the same IP address range, user-agents used during signup, user names or other form-submitted values chosen during signup, etc. Again, these may not always be conclusive.
- Keep an eye on your webserver log files for sudden traffic spikes, especially when a newly-created site is receiving this traffic, and try to identify why you are spending more bandwidth and processing power.
- Try to monitor your free web hosting service for phishing and malware-infected pages. For example, you can use the Google Safe Browsing API to regularly test URLs from your service, or sign up to receive alerts for your AS.
- Come up with a few sanity checks. For example, if you’re running a local Polish free web hosting service, what are the odds of thousands of new and legitimate sites in Japanese being created overnight on your service? There’s a number of tools you may find useful for language detection of newly created sites, for example language detection libraries or the Google Translate API v2.
Last but not least, if you run a free web hosting service be sure to monitor your services for sudden activity spikes that may indicate a spam attack in progress.
For more tips on running a quality hosting service, have a look at our previous post. Lastly, be sure to sign up and verify your site in Google Webmaster Tools so we may be able to notify you when needed or if we see issues.
Crawl Errors: The Next Generation
Webmaster level: All
Crawl errors is one of the most popular features in Webmaster Tools, and
today we’re rolling out some very significant enhancements that will
make it even more useful.
We now detect and report many new types of errors. To help make sense of the new data, we’ve split the errors into two parts: site errors and URL errors.
Site Errors
Site errors are errors that aren’t specific to a particular URL—they affect your entire site. These include DNS resolution failures, connectivity issues with your web server, and problems fetching your robots.txt file. We used to report these errors by URL, but that didn’t make a lot of sense because they aren’t specific to individual URLs—in fact, they prevent Googlebot from even requesting a URL! Instead, we now keep track of the failure rates for each type of site-wide error. We’ll also try to send you alerts when these errors become frequent enough that they warrant attention.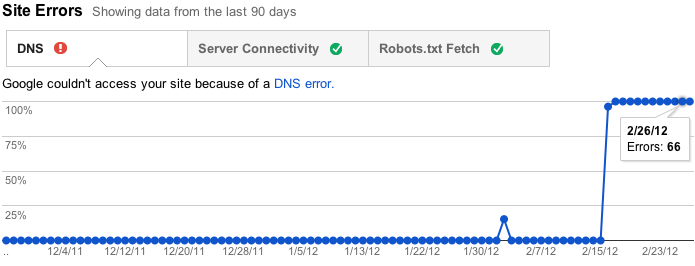 |
| View site error rate and counts over time |
Furthermore, if you don’t have (and haven’t recently had) any problems in these areas, as is the case for many sites, we won’t bother you with this section. Instead, we’ll just show you some friendly check marks to let you know everything is hunky-dory.
 |
| A site with no recent site-level errors |
URL errors
URL errors are errors that are specific to a particular page. This means that when Googlebot tried to crawl the URL, it was able to resolve your DNS, connect to your server, fetch and read your robots.txt file, and then request this URL, but something went wrong after that. We break the URL errors down into various categories based on what caused the error. If your site serves up Google News or mobile (CHTML/XHTML) data, we’ll show separate categories for those errors. |
| URL errors by type with full current and historical counts |
Less is more
We used to show you at most 100,000 errors of each type. Trying to consume all this information was like drinking from a firehose, and you had no way of knowing which of those errors were important (your homepage is down) or less important (someone’s personal site made a typo in a link to your site). There was no realistic way to view all 100,000 errors—no way to sort, search, or mark your progress. In the new version of this feature, we’ve focused on trying to give you only the most important errors up front. For each category, we’ll give you what we think are the 1000 most important and actionable errors. You can sort and filter these top 1000 errors, let us know when you think you’ve fixed them, and view details about them.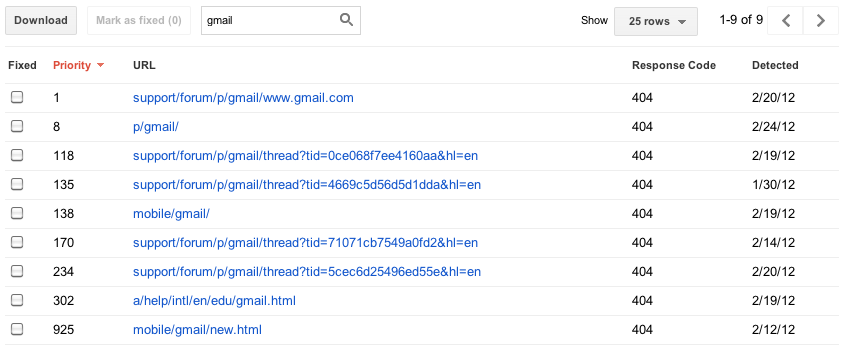 |
| Instantly filter and sort errors on any column |
Some sites have more than 1000 errors of a given type, so you’ll still be able to see the total number of errors you have of each type, as well as a graph showing historical data going back 90 days. For those who worry that 1000 error details plus a total aggregate count will not be enough, we’re considering adding programmatic access (an API) to allow you to download every last error you have, so please give us feedback if you need more.
We've also removed the list of pages blocked by robots.txt, because while these can sometimes be useful for diagnosing a problem with your robots.txt file, they are frequently pages you intentionally blocked. We really wanted to focus on errors, so look for information about roboted URLs to show up soon in the "Crawler access" feature under "Site configuration".
Dive into the details
Clicking on an individual error URL from the main list brings up a detail pane with additional information, including when we last tried to crawl the URL, when we first noticed a problem, and a brief explanation of the error. |
| Details for each URL error |
From the details pane you can click on the link for the URL that caused the error to see for yourself what happens when you try to visit it. You can also mark the error as “fixed” (more on that later!), view help content for the error type, list Sitemaps that contain the URL, see other pages that link to this URL, and even have Googlebot fetch the URL right now, either for more information or to double-check that your fix worked.
 |
| View pages which link to this URL |
Take action!
One thing we’re really excited about in this new version of the Crawl errors feature is that you can really focus on fixing what’s most important first. We’ve ranked the errors so that those at the top of the priority list will be ones where there’s something you can do, whether that’s fixing broken links on your own site, fixing bugs in your server software, updating your Sitemaps to prune dead URLs, or adding a 301 redirect to get users to the “real” page. We determine this based on a multitude of factors, including whether or not you included the URL in a Sitemap, how many places it’s linked from (and if any of those are also on your site), and whether the URL has gotten any traffic recently from search.Once you think you’ve fixed the issue (you can test your fix by fetching the URL as Googlebot), you can let us know by marking the error as “fixed” if you are a user with full access permissions. This will remove the error from your list. In the future, the errors you’ve marked as fixed won’t be included in the top errors list, unless we’ve encountered the same error when trying to re-crawl a URL.
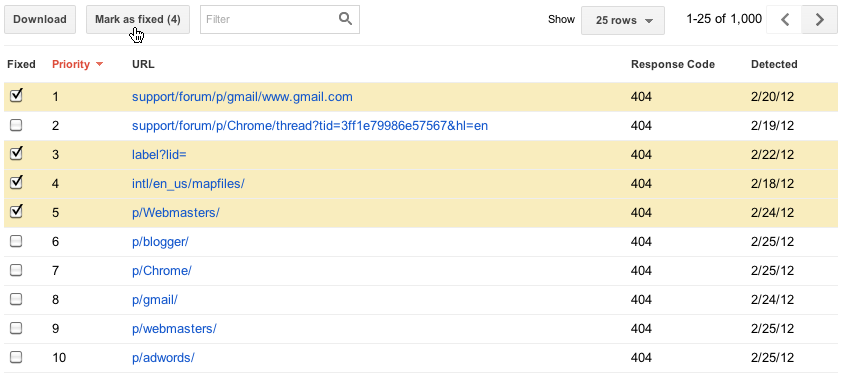 |
| Select errors and mark them as fixed |
We’ve put a lot of work into the new Crawl errors feature, so we hope that it will be very useful to you. Let us know what you think and if you have any suggestions, please visit our forum!
Video about pagination with rel=“next” and rel=“prev”
Webmaster Level: Beginner to Intermediate
If you’re curious about the rel=”next” and rel=prev” for paginated content announcement we made several months ago, we filmed a video covering more of the basics of pagination
to help answer your questions. Paginated content includes things like
an article that spans several URLs/pages, or an e-commerce product
category that spans multiple pages. With rel=”next” and rel=”prev”
markup, you can provide a strong hint to Google that you would like us
to treat these pages as a logical sequence, thus consolidating their
linking properties and usually sending searchers to the first page. Feel
free to check out our presentation for more information:
Slides from the pagination video
Additional resources about pagination include:
- Webmaster Central Blog post announcing support of rel=”next” and rel=”prev”
- Webmaster Help Center article with more implementations of rel=”next” and rel=”prev”
- Webmaster Forum thread with our answers to the community’s in-depth questions, such as:
Does rel=next/prev also work as a signal for only one page of the series (page 1 in most cases?) to be included in the search index? Or would noindex tags need to be present on page 2 and on?
When you implement rel="next" and rel="prev" on component pages of a series, we'll then consolidate the indexing properties from the component pages and attempt to direct users to the most relevant page/URL. This is typically the first page. There's no need to mark page 2 to n of the series with noindex unless you're sure that you don't want those pages to appear in search results.
Should I use the rel next/prev into [sic] the section of a blog even if the two contents are not strictly correlated (but they are just time-sequential)?
In regard to using rel=”next” and rel=”prev” for entries in your blog that “are not strictly correlated (but they are just time-sequential),” pagination markup likely isn’t the best use of your time -- time-sequential pages aren’t nearly as helpful to our indexing process as semantically related content, such as pagination on component pages in an article or category. It’s fine if you include the markup on your time-sequential pages, but please note that it’s not the most helpful use case.
We operate a real estate rental website. Our files display results based on numerous parameters that affect the order and the specific results that display. Examples of such parameters are “page number”, “records per page”, “sorting” and “area selection”...
It sounds like your real estate rental site encounters many of the same issues that e-commerce sites face... Here are some ideas on your situation:
1. It’s great that you are using the Webmaster Tools URL parameters feature to more efficiently crawl your site.
2. It’s possible that your site can form a rel=”next” and rel=”prev” sequence with no parameters (or with default parameter values). It’s also possible to form parallel pagination sequences when users select certain parameters, such as a sequence of pages where there are 15 records and a separate sequence when a user selects 30 records. Paginating component pages, even with parameters, helps us more accurately index your content.
3. While it’s fine to set rel=”canonical” from a component URL to a single view-all page, setting the canonical to the first page of a parameter-less sequence is considered improper usage. We make no promises to honor this implementation of rel=”canonical.”
Remember that if you have paginated content, it’s fine to leave it as-is and not add rel=”next” and rel=”prev” markup at all. But if you’re interested in pagination markup as a strong hint for us to better understand your site, we hope these resources help answer your questions!
Upcoming changes in Google’s HTTP Referrer
Webmaster level: all
Protecting users’ privacy is a priority for us and it’s helped drive recent changes. Helping users save time is also very important; it’s explicitly mentioned as a part of our philosophy. Today, we’re happy to announce that Google Web Search will soon be using a new proposal to reduce latency when a user of Google’s SSL-search clicks on a search result with a modern browser such as Chrome.
Starting in April, for browsers with the appropriate support, we will be
using the "referrer" meta tag to automatically simplify the referring URL
that is sent by the browser when visiting a page linked from an organic
search result. This results in a faster time to result and more
streamlined experience for the user.
What does this mean for sites that receive clicks from Google search results? You may start to see "origin" referrers—Google’s homepages (see the meta referrer specification
for further detail)—as a source of organic SSL search traffic. This
change will only affect the subset of SSL search referrers which already
didn’t include the query terms. Non-HTTPS referrals will continue to
behave as they do today. Again, the primary motivation for this change
is to remove an unneeded redirect so that signed-in users reach their
destination faster.
Website analytics programs can detect these organic search requests by
detecting bare Google host names using SSL (like
"https://www.google.co.uk/"). Webmasters will continue see the same data
in Webmasters Tools—just as before, you’ll receive an aggregated list of the top search queries that drove traffic to their site.
We will continue to look into further improvements to how search query
data is surfaced through Webmaster Tools. If you have questions,
feedback or suggestions, please let us know through the Webmaster Tools Help Forum.



















